In addition to PostgreSQL's built-in continuous archiving mechanism and PostgreSQL streaming replication that enables the continuous streaming and replication from a primary database server to a secondary, replication, server, you can also backup and restore the CTERA portal database to and from an S3 bucket.
The CTERA Backup to S3 includes backing up critical portal configurations, including networking, certificates, and passwords required to reconnect to the restored database.
Using CTERA Backup to S3 allows administrators to back up the portal settings, base database backup, and archival logs automatically to a designated S3 bucket, ensuring data integrity and availability through consistent backups while providing administrators with a user-friendly interface for backup configuration and status monitoring.
Using CTERA Backup to S3 provides an off-site database backup mechanism for disaster recovery.
Backing up the CTERA Portal database to an S3 bucket and restoring it from the S3 bucket can be done in one of the following ways:
- Automatically, by configuration in the portal user interface, as described in Configuring Backups to an S3 Bucket.
- Using command line scripts for restoring the database.
- Using the CTERA SDK to automate both configuration of the backup and restoring the database.
How It Works
CTERA Backup to S3 synchronizes the portal database with the specified S3 bucket. Delta updates are incremental and only modified data, new or updated, is transferred from the portal database to the S3 bucket. By only transferring changed data, CTERA Backup to S3 reduces bandwidth usage and speeds up the synchronization process. CTERA Backup to S3 also deletes data from the S3 bucket that no longer exists in the portal database.
For an environment with a large portal database, using CTERA Backup to S3 periodically can reduce downtime.
Configuring Backups to an S3 Bucket
An archive pool must have been created on the primary database server. For details refer to the installation documentation for your environment. For example, for a portal running in an ESXi environment, see here.
Before enabling backing up to an S3 bucket, the base backup of the portal database must be error free.
To configure an S3 bucket for backups from the user interface:
-
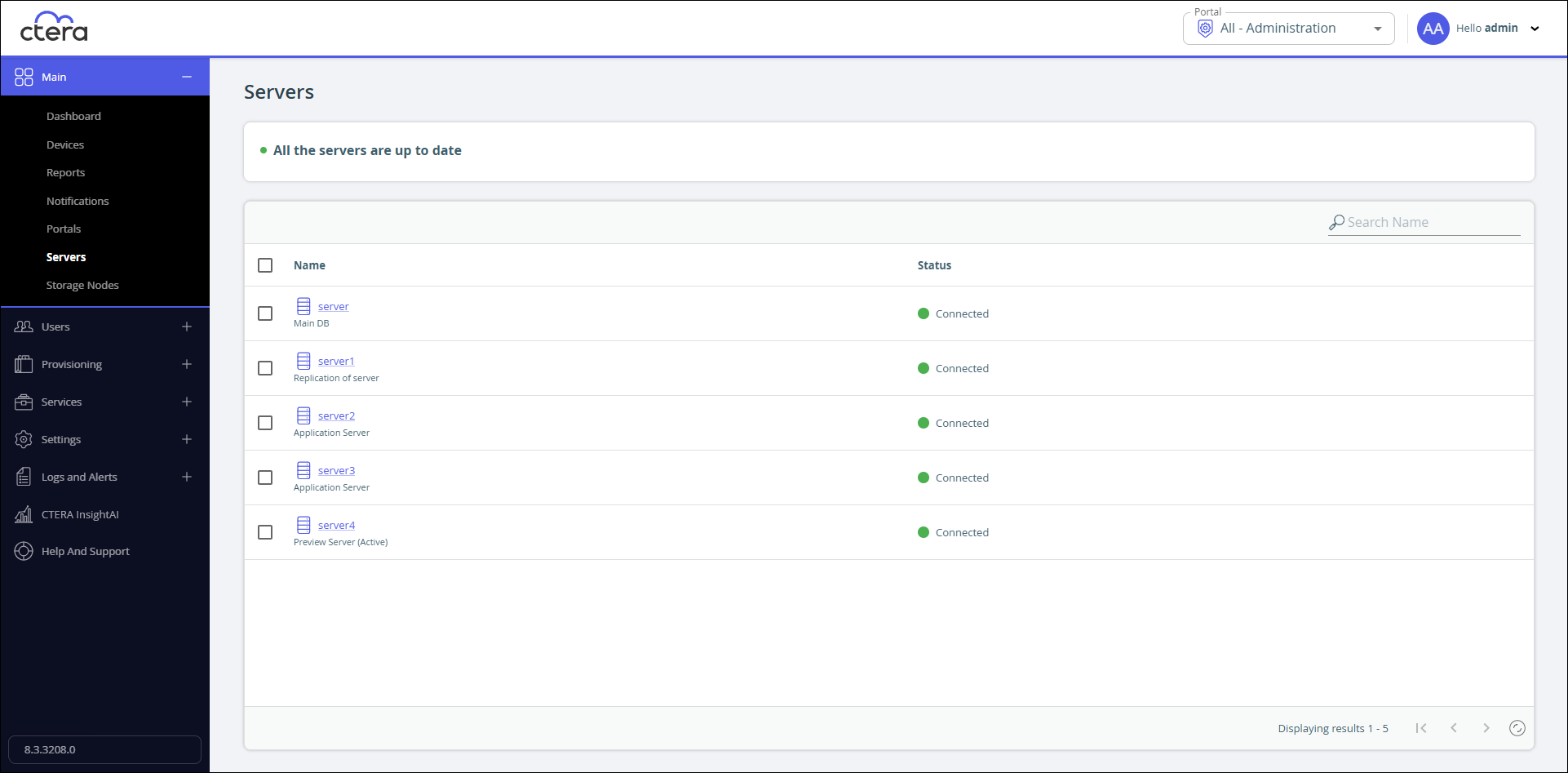
Sign in the portal as a global administrator and click Main > Servers.
The Servers page is displayed.
-
Click the primary database server.
The server window is displayed with the server name as the window title.
-
Click the DB Replication option.
The portal reports the status of its scheduled base backups and transaction log archiving process.
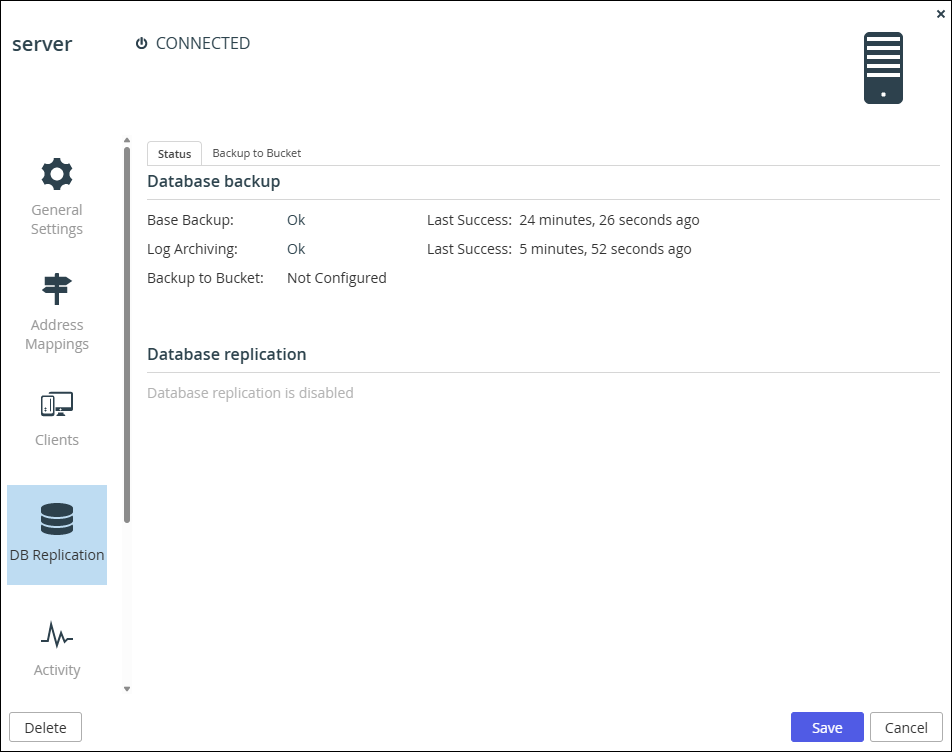
Under Database backup you can see that Backup to Bucket is not configured. -
Click the Backup to Bucket tab.
-
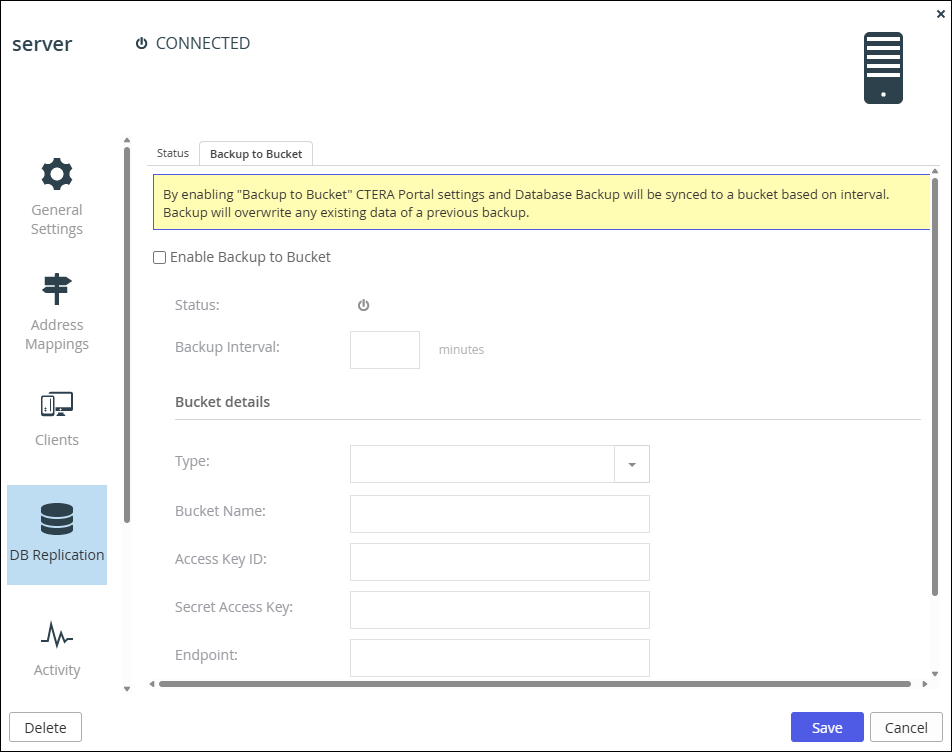
Check Enable Backup to Bucket.
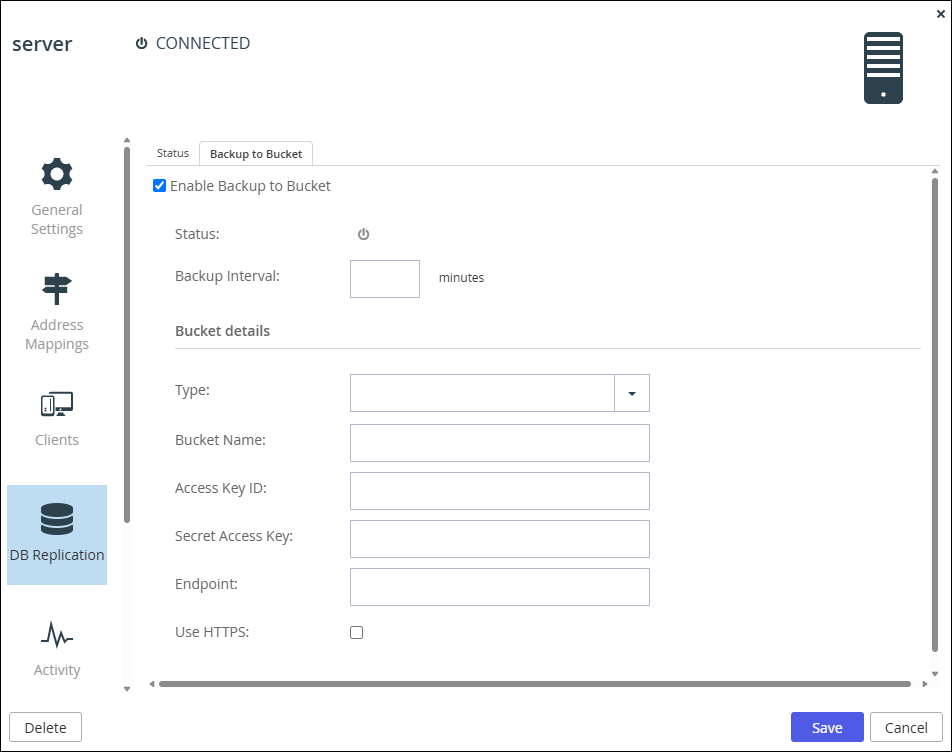
-
Complete the fields as follows:
Backup Interval – The interval between backups from 5 minutes to 43200 minutes (a month).
Under Bucket details define the S3 bucket to use for the database backup.
Type – The type of bucket to use. The following S3 buckets are supported:- Amazon Web Services (S3)
- Cohesity Data Platform (S3)
- DataCore Swarm (S3)
- Dell ObjectScale (S3)
- Dell PowerScale (S3)
- Everpure
- Google Cloud Storage (S3)
- Hitachi Vantara HCP (S3)
- IBM Cloud Object Storage (S3)
- IBM Storage Ceph (S3)
- MinIO Object Storage (S3)
- NetAppS3
- Nutanix (S3)
- Quantum ActiveScale (S3)
- QumulosS3
- Scalitiy ARTESCA (S3)
- VAST Data (S3)
- VSP One Object (S3)
- Wasabi (S3)
- Zadara (S3)
Bucket Name – The name of the bucket. The bucket cannot be a bucket that is used as a storage node nor as the bucket for the CTERA Thumbnails service.
Access Key ID – The bucket access key ID.
Secret Access Key – The bucket secret access key.
Endpoint – The endpoint name of the bucket service. The port for the endpoint can be customized by adding the port after the URL, using a colon (:) separator. The default port is 80.
Use HTTPS – Use HTTPS to connect with the bucket. -
Click Save.
After configuring backups to an S3 bucket the portal database is backed up to the bucket based on the same retention policy on the S3 bucket as is configured on the local archive pool, including the cleanup of old backups.
The Status field in the Backup to Bucket tab indicated the status of the connection.
Monitoring Backups to an S3 Bucket
The administrator can monitor the status of the backup at any time. The status indicator has the following states:
- Not Configured
- Disabled
- OK
- In Progress
- Failed
Both dashboard alerts and email notifications are provided in case or backup failures, for example when there is a disconnection to the S3 bucket. Errors are also written to the system log to ensure timely administrator intervention.
Restoring From the S3 Bucket
To restore the database you need a clean install of a portal server, that has been configured after the initial setup wizard and that includes an archive pool and the same settings of the original primary database server, such as the same backup-history-days for the portal.sh configure-db-recovery backup-history-days command.
Restoring the database can be done to any location.
Run the db_bucket_restore.sh script on the new server to restore the database from the S3 bucket to the portal server.
./db_bucket_restore.sh
Restore PostgreSQL backup and portal settings from bucket usage:
/usr/local/ctera/bin/portal.sh restore_from_bucket <OPTIONS> [ARGS]
OPTIONS:
-u Source bucket URL <s3://bucketname/<server role>>. Example: s3://backupdestination/masterdb
-s Download portal settings from bucket
-p Download PostgreSQL backup from bucket
-f Download PostgreSQL backup and portal settings from bucket
-c Add custom URL (for non-AWS buckets) <aws --endpoint-url http://your-custom-endpoint>
-i Allow self-signed cert - must add path to .crt file <--ca-bundle /path/to/certificate.crt s3 ls>
You can use the portal.sh db-rollback command to restore the database to a specific point in time.