CTERA Fusion enables the content of cloud folders to be accessed using the S3 API, either using supported S3 operations in programs or using an S3 browser application like FileZilla, WinSCP, Cyberduck, CloudBerry, and S3 Browser.
CTERA Fusion supports S3 browsers that use multipart uploads.
The capabilities of CTERA Fusion include:
In-place Read/Write – Enables reading and writing directly to a global file system using the S3 protocol eliminating expensive and time-consuming processes of copying data to external S3 buckets.
Single namespace across file and object – Interact with data generated at the edge using standard object storage S3 protocols, or access cloud-generated data from the edge using NAS protocols. Data is available where you need it, when you need it.
Support for multipart uploads – Benefit from multipart uploads, making ingestion and sharing of large files even more efficient.
Robust security – All data is secured in transit via TLS and encrypted at rest, providing an added layer of protection.
NT-ACL support – File ACLs are preserved.
TCP 443 support – TCP 443 is supported.
Self-signed certificate support – Self-signed certificates can be used.
To set up access to a cloud folder using the S3 API, you need to do the following:
- Set up the CTERA Portal server
- Create an S3 Bucket for the cloud folder
- Create an Access Key ID and Secret Access Key
After these steps, you can access the cloud folder content using the S3 API by providing the following:
- The endpoint for the bucket, defined when you create the bucket
- The Access Key ID
- The Secret Access Key
For details, see Accessing Portal Content Using the S3 API.
Setting Up the CTERA Portal Server
The global administrator must specify at least one portal server as an S3 endpoint. For details, see the description of the S3 Endpoint field in Editing Server Settings:General Settings.
Checking the S3 Endpoint is required on only one server. For high availability, the global administrator can set the S3 Endpoint on more than one server.
Creating an S3 Bucket
To access content you must set up the required cloud folders as buckets, one bucket for each cloud folder.
To create an S3 bucket:
- Select Folders > Buckets in the navigation pane.
The Buckets page opens, displaying all cloud folders linked as S3 buckets.
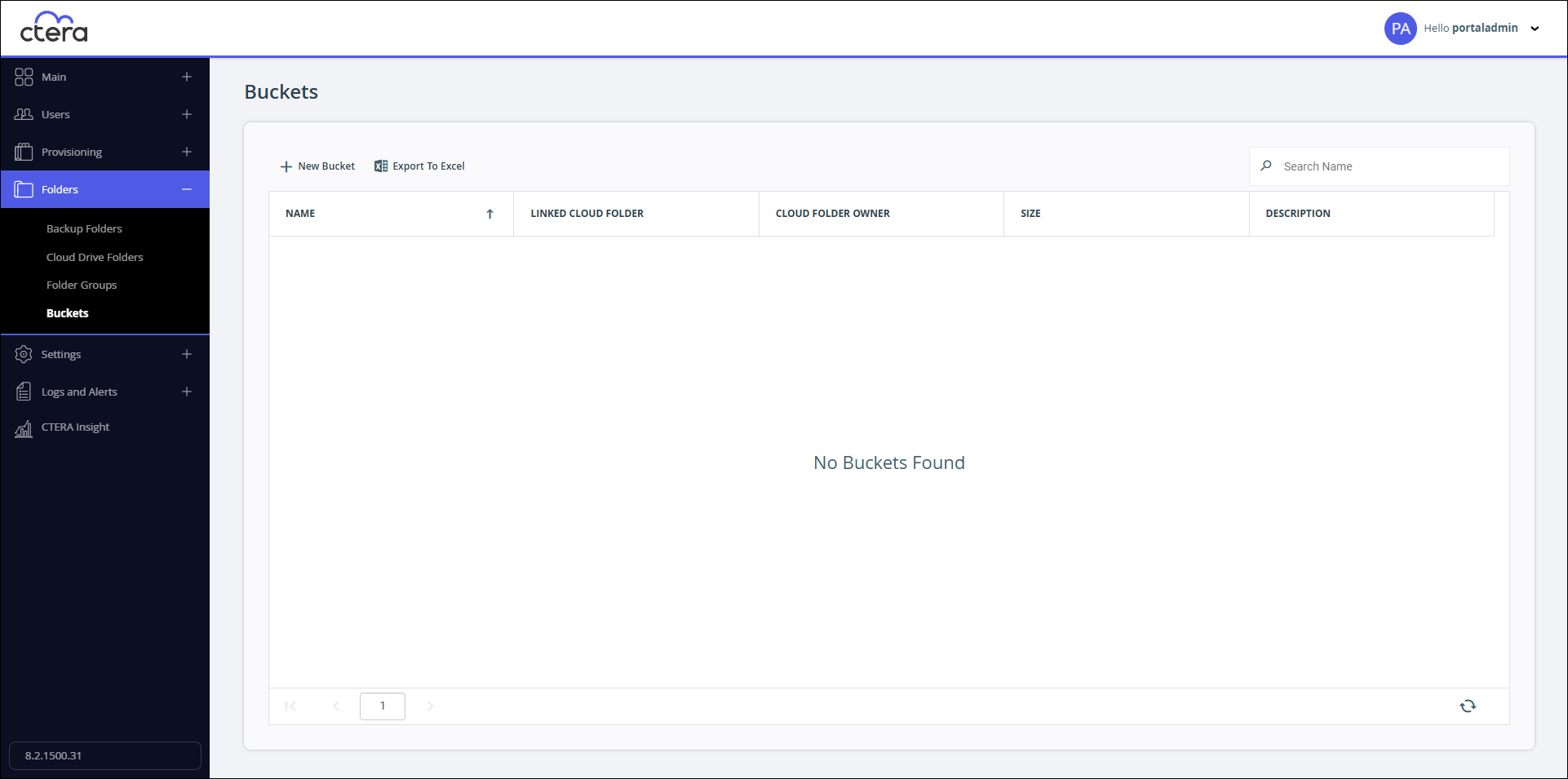
- Click New Bucket.
The New Bucket window is displayed.
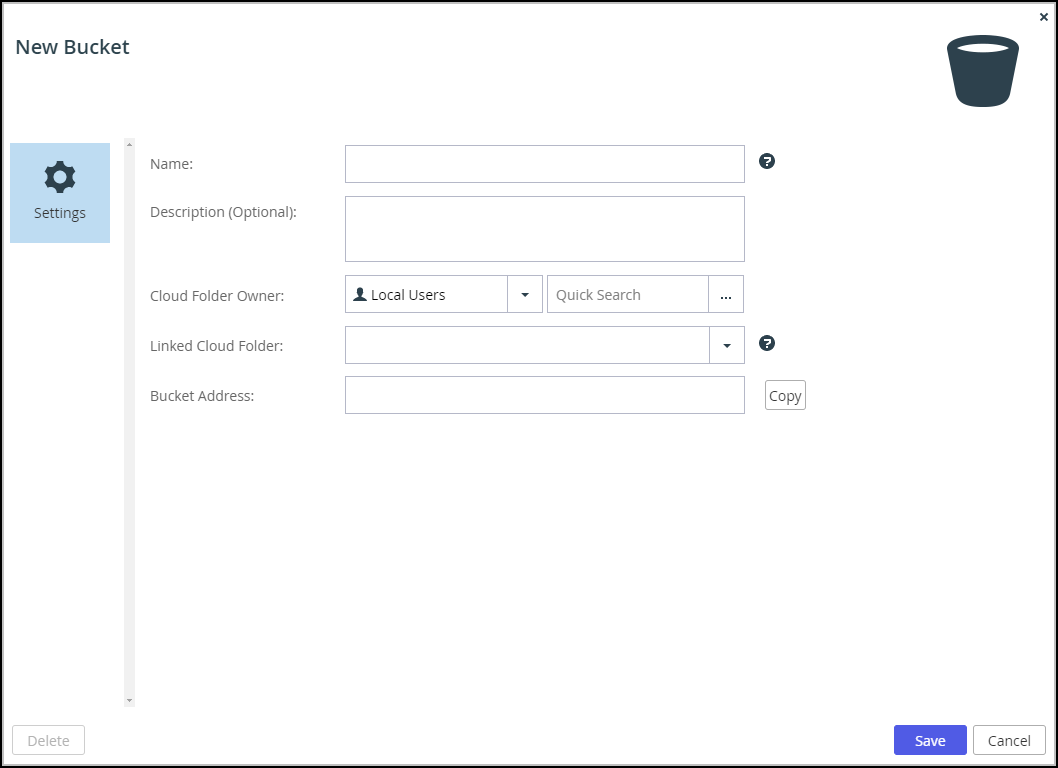
- Complete the fields:
Name – A name for the bucket. The name cannot include uppercase letters. CTERA recommends a name between 3 and 63 characters. Valid characters are lowercase letters, numbers, and special characters.
Description (Optional) – A description for the bucket.
Cloud Folder Owner – The user who owns the bucket. The owner controls access to the bucket using the Access Key ID and Secret Access Key pair created for that user.
Linked Cloud Folder – A folder from the list of folders associated with the folder owner.
Bucket Address – The address for the bucket, generated by CTERA Fusion, and used for the bucket endpoint, as described below in the procedure To get the bucket endpoint. - Click Save.
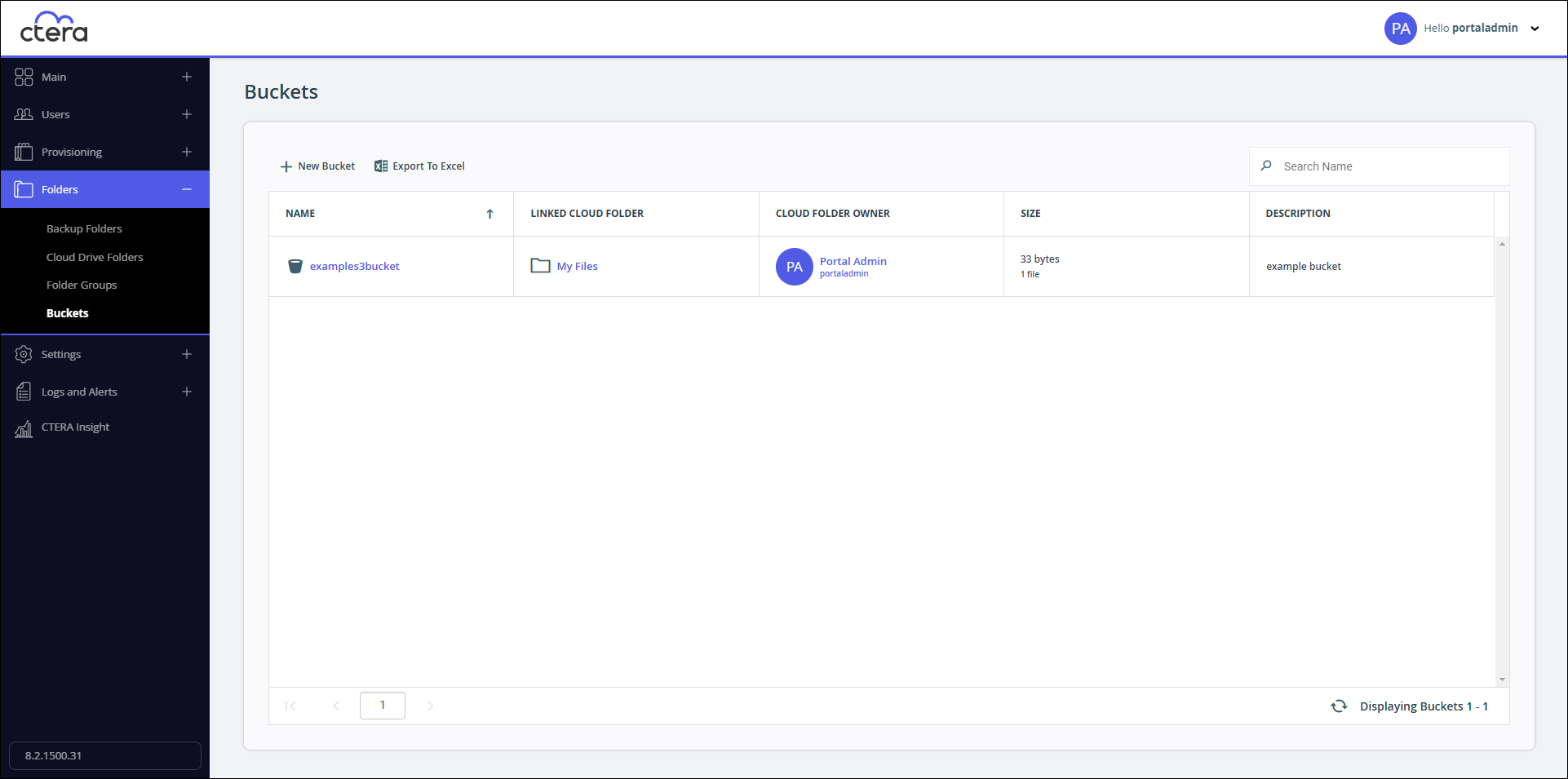
To access the bucket content using the S3 API, you need the endpoint.
To get the bucket endpoint:
- Select Folders > Buckets in the navigation pane.
The Buckets page opens, displaying all cloud folders linked as S3 buckets.
- Click the bucket.
The bucket window is displayed with the name of the bucket as the window title.
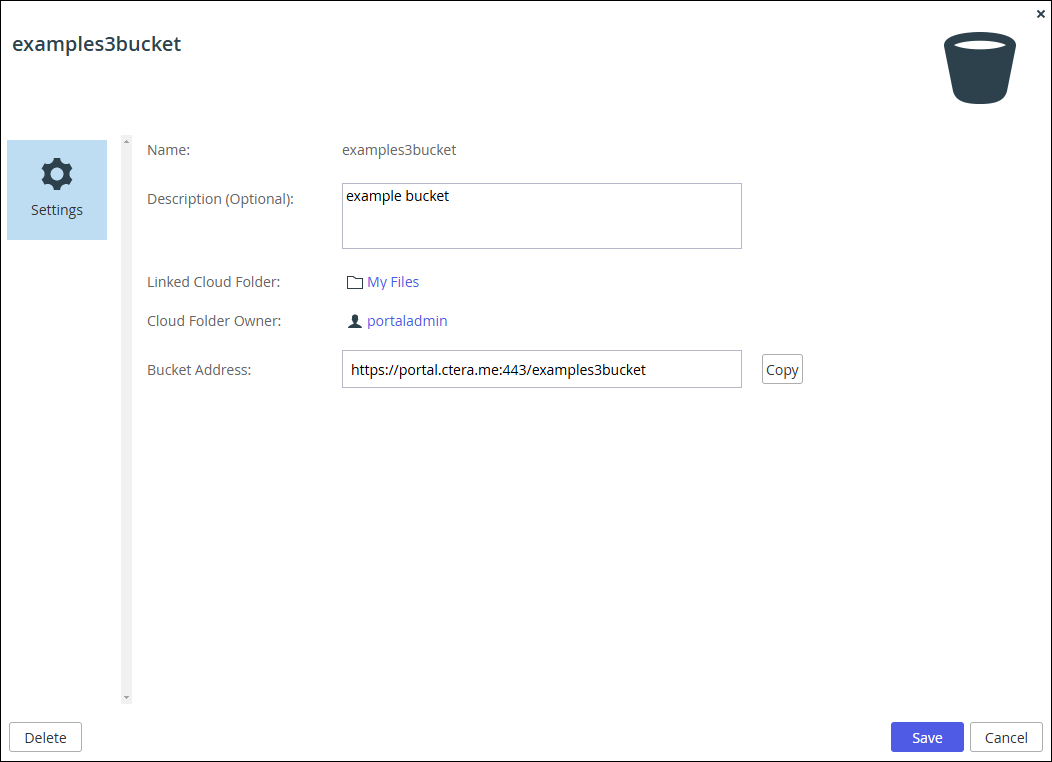
- Copy the Bucket Address to use as the endpoint.Note
The endpoint includes the DNS name and not the IP address. You cannot access the bucket using an endpoint with an IP address.
- Optionally, edit the Description (Optional) field.
- Click Save or Cancel.
You can delete a bucket by selecting the bucket row and clicking Delete and then DELETE in the confirmation window.
Creating Access Key IDs and Secret Access Keys
A single Access Key ID and Secret Access Key pair can be used to access all the buckets assigned for a specific user. Each user can have more than one pair of Access Key IDs and Secret Access Keys, up to a maximum of 100.
Both the administrator can create the Access Key ID and Secret Access Key pair for a user as described in Setting Up API Keys to Access S3 Buckets, or the end user can create the Access Key ID and Secret Access Key pair in the end user portal, as described in Using an S3 Browser.
Accessing Portal Content Using the S3 API
Access to portal content using the S3 API can be done using an S3 browser or in code.
Access via an S3 Browser
You require the following information:
- The endpoint for the bucket
- The Access Key ID
- The Secret Access Key
You enter this information in the S3 browser to access the content, for example using S3 Browser:

Access via Code Using the S3 Protocol
The following S3 operations are supported:
- GetObject
- HeadObject
- DeleteObject
- S3 PutObject
- S3 ListObject
- Copy
- Get Byte Range
- CreateMultipartUpload
- ListMultipartUploads
- UploadPart
- ListParts
- AbortMultipartUpload
- CompleteMultipartUpload
The following operations are not supported:
- Create a bucket
- Versioning
- SignedURLs